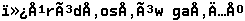


|
|
|
|
| English | Polski |
|
KazFont - free programmer font for Windows
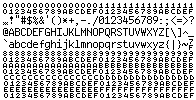
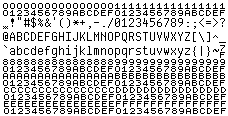
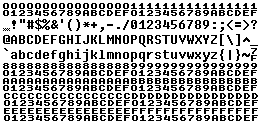
3. Debugging help There are different font requirements for source code editor and debug window, for example we usually set smaller fonts in debug window. If you trace simple strings from the program, then normal font will suffice. But if you work with raw data from serial port, socket or device, you probably want to see exact values of the bytes. KazFont has two solutions for this requirement. 3a. Hex font Instead of the characters, you see hexadecimal values. All code positions are filled, so full 256 character range is visible. You can change any text editor to a hex viewer, even common Notepad in Windows. Control characters below 0x20 can be sometimes improperly displayed by the text editor, especially 0x00, 0x09, 0x0A and 0x0D.
3b. UTF8 font It also displays character values below 0x20, but shows real characters in the range of 0x20 - 0x7E. The space character is marked so it is not an empty space. The font displays byte values, so why is the name UTF8 ? KazFont UTF8 has character images of these values (≥ 0xC0) shifted right by one pixel, so you can easy observe when multibyte Unicode character starts, as in the samples below. Exact view of the text depends on text editor logic.
Samples: Original text encoded in CP1250 and saved as UTF-8: The same file viewed as ASCII in Western encoding: The same file viewed using KazFont UTF8 in different font sizes, the UTF-8 pairs can be easily noticed: 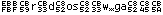 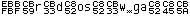 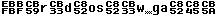 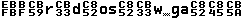 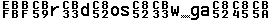
Bytes EF BB BF marks text as UTF-8. |
Copyright © 2004-2015 Omega Computer